
Over 40% of RAG Systems in Production Generate Hallucinated Answers
An EdTech Platform’s AI Assistant Was One of Them.
They Called Us to Fix It.
RAG Hallucinations occur when a retrieval-augmented generation system delivers confident but fabricated answers because the retrieval layer returned irrelevant context to the language model. This is not a theoretical risk – it is a production failure we were called in to fix.
Seven months ago, an established EdTech platform contacted our team – not to build something new, but to fix an existing deployment. They had invested around $35K in a RAG-powered study assistant that answered student and instructor queries using a 3,000-document content library of course transcripts, study guides, assessment rubrics, and research reading lists. The team rolled the system out to more than 1,500 enrolled students.
In demos, the RAG chatbot performed flawlessly. It explained learning concepts with clarity and surfaced relevant materials with proper references. Three months after launch, a student flagged something alarming: the assistant had cited a research paper that did not exist. It was a fully fabricated academic reference – complete with a plausible author name, journal title, publication year, and findings summary. The student had nearly submitted it in a university assignment.
The system had not crashed or flagged errors. It answered with the same confident, wellstructured prose it always used. Students had no way to distinguish a grounded answer from a hallucination. The product team’s question was not about rebuilding the model. It was about understanding why a RAG system that performed flawlessly in testing was actively misleading users in production.
That question – “Why well-built AI systems fabricate answers and how to fix RAG hallucinations at scale — is what this article addresses”.
What Caused the RAG Hallucination Problem
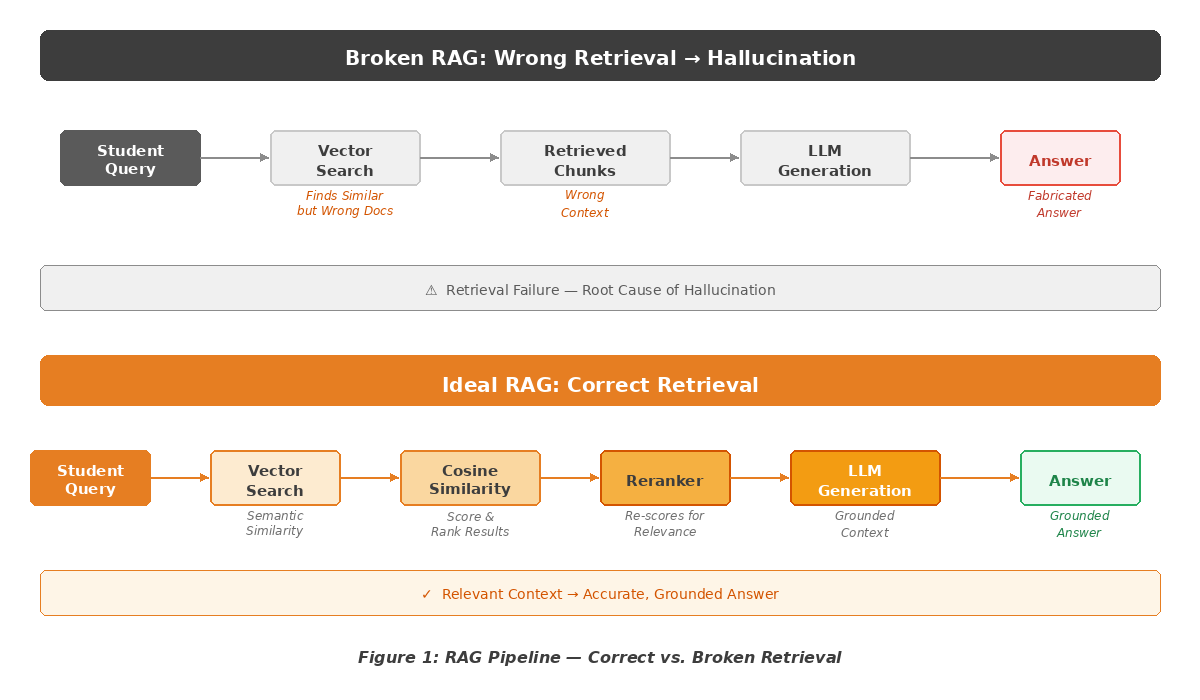
The RAG hallucination was caused by a retrieval quality failure, not an LLM deficiency. After a week-long audit, we confirmed the language model was well-configured, the document ingestion pipeline was technically sound, and the embedding model was appropriate for the domain. The failure was in the one component everyone treats as a solved problem: retrieval quality.
A RAG system works in two stages. First, it retrieves relevant document chunks from a knowledge base using vector similarity search. Then, it generates an answer by feeding those chunks to the language model as context. The platform’s system used pure vector search: convert the query to an embedding, find the nearest chunks by cosine similarity, and pass the top five results to the model.
This approach works when query intent directly matches the most similar chunk. It fails catastrophically when the semantically nearest chunks are topically adjacent but contextually wrong. In the EdTech domain, a student query about gradient descent in a machine learning course might return chunks from a calculus study guide, a physics module on slopes, or an unrelated statistics rubric. All score high on semantic similarity. None actually answer the question.
When the language model receives wrong context, it does not say “I don’t have enough information.” It does what LLMs are trained to do: synthesize a fluent, confident answer from whatever it receives. With irrelevant context, that answer becomes a hallucination – not random noise, but a plausible-sounding fabrication anchored to fragments of the wrong documents
This is the core RAG hallucination problem. The LLM is not broken. The retrieval step is broken. And because the output looks authoritative, users cannot detect the failure without independently verifying every answer.
LLM Fabrication Is a Systemic Pattern, Not an Isolated Bug
RAG hallucinations are not isolated incidents – they are a systemic retrieval failure pattern we have observed across four organizations in the past year. Deployments spanned EdTech platforms, financial compliance tools, healthcare documentation assistants, and enterprise HR policy bots. The LLMs ranged from GPT-4o to Gemini to open-source models. Vector databases included Pinecone, Weaviate, and pgvector. The surface details varied. The failure pattern was identical: strong demo performance on curated test queries, retrieval treated as infrastructure rather than logic, no output validation mechanism, and late discovery of hallucinations by users rather than monitoring systems.
In three of the four cases, the language model itself performed correctly given the context it received. The failure was entirely in the retrieval layer – the component that determines what context the model sees before generating a response.
Preventing Retrieval-Augmented Generation Errors in Production
A production-grade RAG system must treat retrieval as an engineering discipline, not a configuration step. RAG is often described as “giving AI access to your documents.” That is technically accurate but operationally misleading. RAG is only as trustworthy as its worst retrieval result. If the retrieval step sends wrong documents, the model generates a confident wrong answer. The quality of any RAG system is fundamentally a retrieval quality problem, not a language model problem.
A production-grade RAG system requires hybrid search combining dense vector search with sparse keyword search (BM25) so that exact-match queries are not lost to embedding noise. It requires reranking – a second-pass relevance model that re-scores retrieved chunks based on query-document alignment, not just similarity. In addition, context validation applies automated checks to confirm retrieved chunks contain the entities, dates, or terms present in the query. Finally, grounded citations link every output to a specific source chunk with a confidence score and return a structured “I don’t know” when the model cannot cite a source. And it requires continuous monitoring of retrieval hit rates, answer confidence distributions, and user correction signals.
How We Eliminated AI Hallucinations in the EdTech RAG System
Phase 1: Hybrid Search and Reranking (Weeks 1–2)
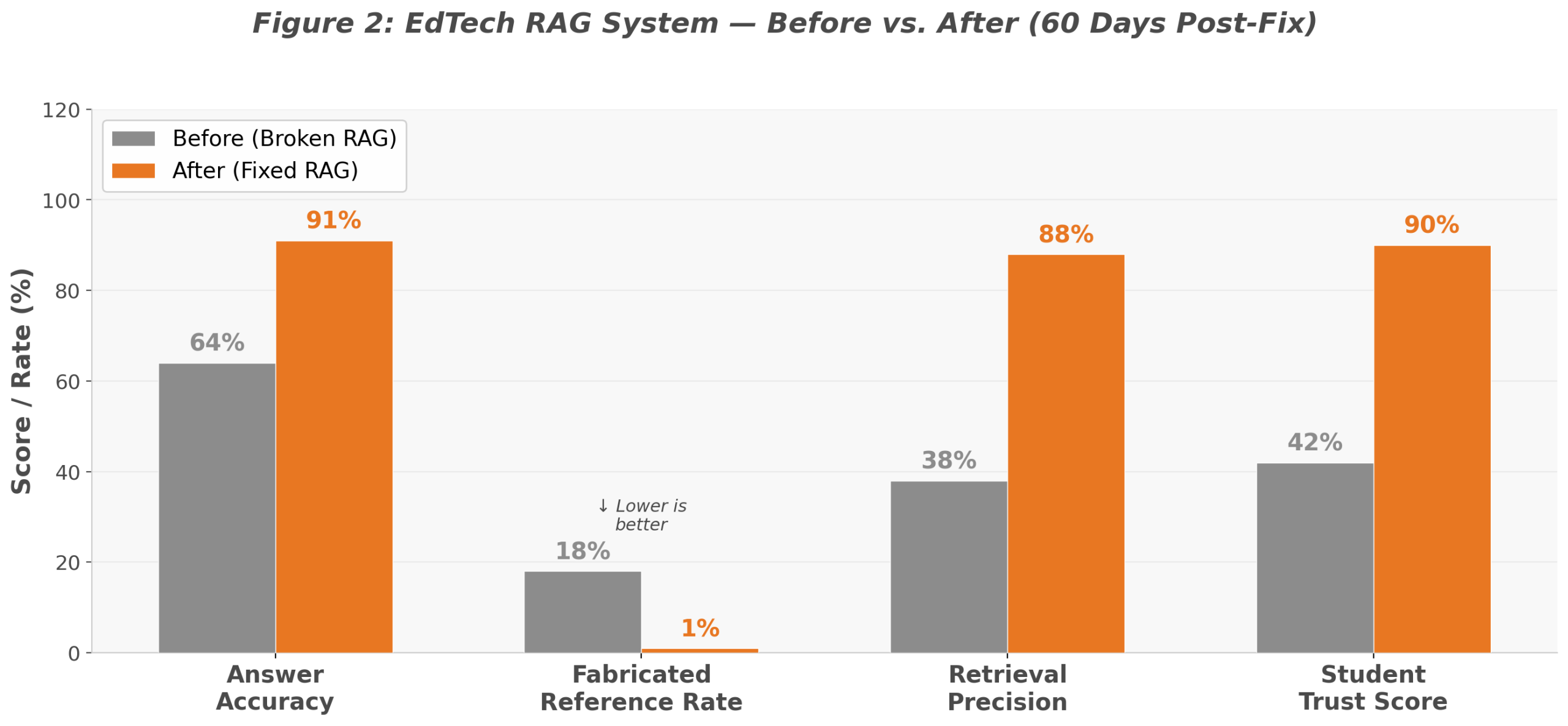
Hybrid search with reranking eliminated 84% of irrelevant retrievals that pure vector search had missed – the single biggest driver of RAG hallucinations in this deployment. We replaced the pure vector search with a hybrid pipeline combining semantic embeddings with BM25 keyword search. Both systems returned independent ranked lists fused using Reciprocal Rank Fusion. We added a Cohere reranker – a small transformer fine-tuned for educational content relevance – that re-scored the fused top-20 results and returned only the top-5 by rerank score.
On a held-out test set of 120 student queries from the previous six months, the reranking step eliminated irrelevant top-5 retrievals in 84% of cases where pure vector search had failed. The fabricated academic reference rate dropped from 18% of queries to under 2%.
Phase 2: Context Validation and Grounded Citations (Weeks 3–4)
We added a validation layer between retrieval and generation. Before passing chunks to the LLM, the system first ran three automated checks. It verified concept overlap to confirm the retrieved chunk referenced the same topic, module name, or learning objective as the query. Next, it evaluated subject coherence to ensure all top-5 chunks came from the same course subject and level. Finally, it applied a confidence threshold to confirm the reranker score exceeded a defined minimum.
If a query failed validation, the system triggered a structured fallback: “I could not find sufficient content in your course materials to answer this confidently. Here are the closest sources I found.” This safeguard eliminated an entire class of RAG hallucinations, particularly those caused by out-of-scope queries. Additionally, the system linked every generated answer to its source chunks using explicit citation markers. As a result, students and instructors could click any claim and immediately view the exact passage from which the response was derived.
Results: Retrieval Fixes Reduced RAG Hallucinations by 94%
Answer accuracy jumped from 64% to 91% and the fabricated reference rate dropped by 94% within 60 days of implementing the retrieval fixes.
The solution was never a better language model – it was a better retrieval system, combined with the discipline to force the model to say ‘I don’t know’ when the evidence wasn’t there.
The fix was not a better language model. It was a better retrieval system – and the discipline to make the model say “I don’t know” when it should.
5 Steps to Prevent RAG Hallucinations in Production
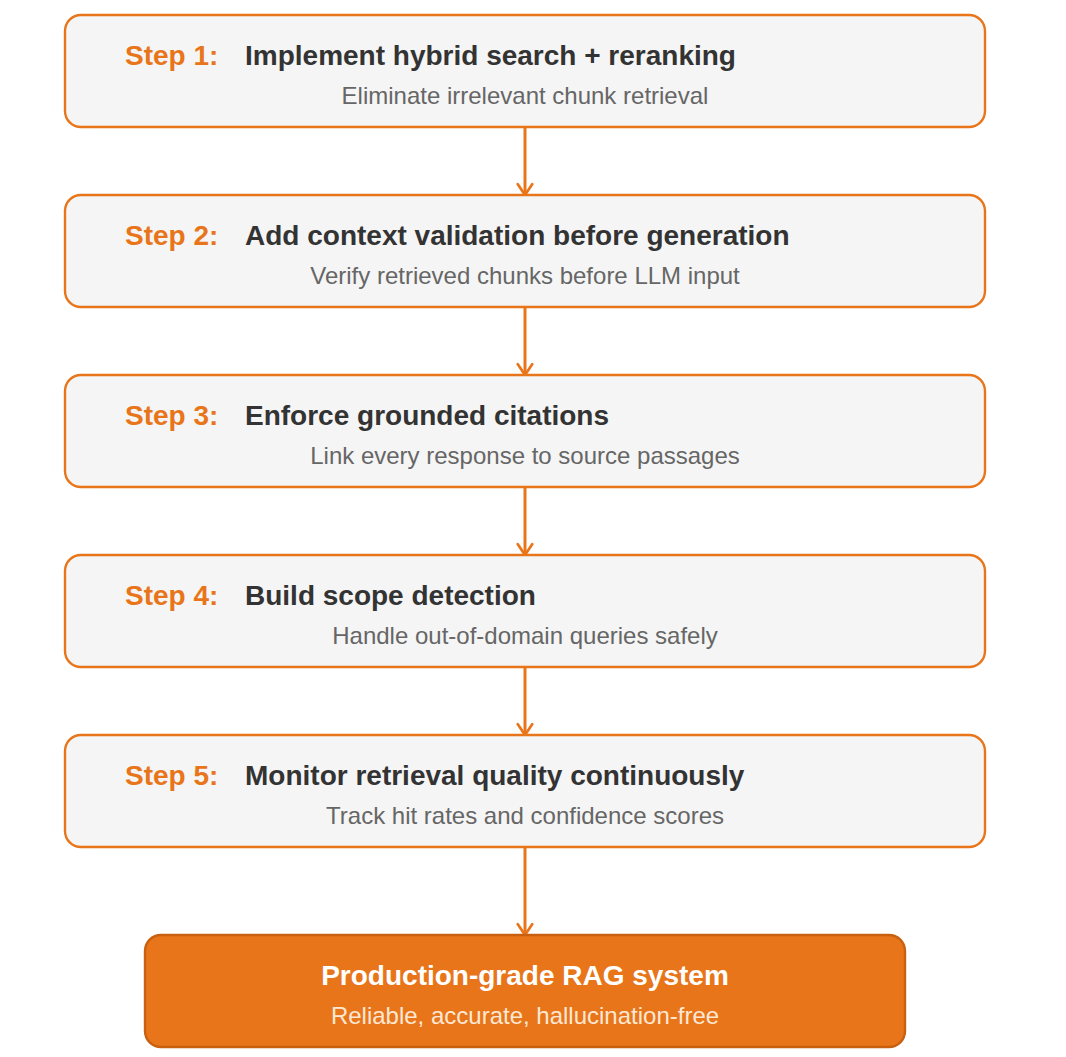
Step 1: Replace Vector Search with Hybrid Search and Reranking Pure vector search retrieves semantically similar but contextually wrong chunks — the leading cause of RAG hallucinations. Combine dense vector search with BM25 keyword search and add a cross-encoder reranker to re-score results by actual relevance. This alone eliminates the majority of irrelevant retrievals in production RAG pipelines.
Step 2: Add Context Validation Before LLM Generation Never pass unverified chunks to the language model. Build a validation layer that checks concept overlap, subject coherence, and confidence thresholds before generation. Queries that fail validation should trigger a structured fallback – not a hallucinated response from weak context.
Step 3: Enforce Grounded Citations to Reduce AI Fabrication Every RAG system response must link to its source passage. If the model cannot cite a verifiable source, it should return “insufficient information” instead of generating an answer. Grounded citations are the primary mechanism for AI hallucination detection in retrieval-augmented generation systems.
Step 4: Build Scope Detection to Handle Out-of-Domain Queries When a query falls outside the knowledge base, any generated answer is fabricated by definition. Implement query scope detection that identifies out-of-domain requests and routes them to a fallback response – preventing the most common source of LLM hallucinations in enterprise RAG deployments.
Step 5: Monitor RAG Retrieval Quality to Prevent Accuracy Degradation Retrieval precision degrades silently as knowledge bases grow. Set up continuous monitoring for retrieval hit rates, answer confidence scores, and user correction signals. Without retrieval quality monitoring, hallucination rates increase undetected until a user catches a critical error.
The Bottom Line: RAG Hallucinations Are a Retrieval Problem
RAG hallucinations stem from a retrieval engineering failure, not a language model deficiency. The LLM performs exactly as designed – it generates a coherent response from the context it receives. However, if the retrieval layer delivers wrong context, the model produces a confidently wrong answer. Therefore, building a trustworthy RAG system demands treating retrieval quality with the same engineering discipline you apply to the rest of your infrastructure: hybrid search, reranking, context validation, grounded citations, and continuous monitoring.
Ultimately, if you operate a RAG system in production without monitoring retrieval precision, you cannot distinguish whether your users are receiving correct answers or trusting confident fabrications.
Fix RAG Hallucinations with ScriptsHub Technologies
ScriptsHub Technologies has audited and eliminated RAG hallucinations across EdTech, healthcare, and enterprise platforms. As a result, our engineers now offer a complimentary AI Production Readiness Assessment – a focused 90-minute diagnostic that pinpoints retrieval quality gaps and delivers a prioritized roadmap to improve RAG accuracy. No pitch. Just actionable engineering guidance from a team that has completed the audits. Book your free consultation today or follow us on LinkedIn for proven insights on RAG reliability and production AI architecture.
Frequently Asked Questions
1. What causes hallucinations in RAG systems?
RAG hallucinations occur when retrieval returns irrelevant or low-quality context. The language model then generates confident but incorrect answers. Common causes include poor vector search, missing reranking, weak chunking strategy, and lack of citation grounding. Improving retrieval quality is the most effective way to prevent RAG hallucinations.
2. How do you prevent hallucinations in RAG pipelines?
Prevent RAG hallucinations by using hybrid search, reranking, context validation, grounded citations, and fallback responses. These controls ensure the model only answers using verified retrieved content. Monitoring retrieval precision and confidence thresholds further reduces hallucinated responses in production RAG deployments.
3. Why does vector search alone cause RAG hallucinations?
Vector search retrieves semantically similar content, not necessarily correct context. This can surface topically related but incorrect documents. When the language model uses this context, it generates fabricated answers. Hybrid search with BM25 and reranking improves retrieval accuracy and reduces hallucinations.
4. What is the best retrieval strategy for RAG systems?
The best RAG retrieval strategy combines vector search, keyword search (BM25), and reranking. Hybrid retrieval improves recall, while reranking improves precision. Adding context validation and citation grounding ensures responses remain traceable, accurate, and resistant to hallucinations.
5. How do grounded citations reduce RAG hallucinations?
Grounded citations link generated answers to specific retrieved source passages. This forces the system to generate responses only from verifiable content. If no citation exists, the system returns a fallback instead of fabricating an answer, significantly reducing hallucination risk.
6. How do you monitor RAG retrieval quality in production?
Monitor RAG retrieval quality using hit rate tracking, reranker confidence scores, citation coverage, and user feedback signals. Declining retrieval precision often indicates rising hallucination risk. Continuous evaluation helps detect retrieval drift and maintain reliable AI answers over time.
Leave a Reply