
A Three-Layer Defense Architecture for Exactly-Once Processing in Production
Dozens of duplicate enrollments per day. Double billing. Inflated class rosters. Financial aid discrepancies. All caused by a single missing API pattern – idempotency. At ScriptsHub Technologies, we resolved this for an EdTech platform processing thousands of concurrent enrollment requests by implementing a three-layer idempotent API architecture using Redis, distributed locks, and database constraints.
The client’s platform had a non-idempotent POST endpoint with no server-side deduplication. Every API call created a new enrollment record regardless of whether an identical request had already been processed. In distributed systems – where network failures, load balancer retries, and automatic client retries are routine – this is a well-known anti-pattern that leads to data corruption at scale.
This case study documents the root cause, the diagnostic approach, and the exact three-layer idempotent API architecture we built to achieve exactly-once processing in production. The pattern has since been deployed across EdTech, healthcare, and financial services engagements.
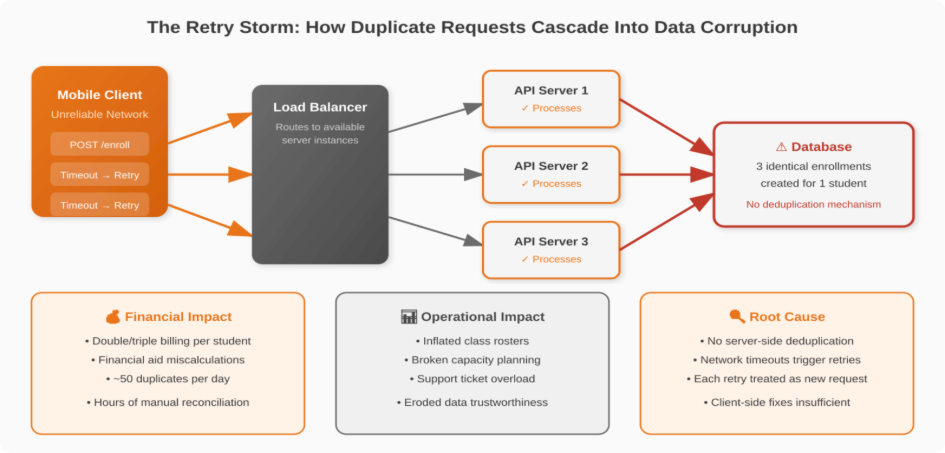
Why Non-Idempotent POST Endpoints Fail in Distributed Systems
The issue surfaced during high-traffic registration windows when the system processed thousands of concurrent enrollment requests. Mobile clients on unreliable networks would timeout and retry failed enrollment requests. The API – which had performed reliably at lower volumes – had no server-side deduplication mechanism. Each retry was treated as a brand-new enrollment.
The client’s internal team attempted several fixes before engaging ScriptsHub: client-side throttling, frontend deduplication, and manual reconciliation. None addressed the root cause – because duplicate request prevention must happen at the server level. Client-side solutions cannot account for load balancer retries, connection drops mid-response, or requests routed to different backend servers.
When we analyzed the API logs, we observed consistent spikes of dozens of duplicate enrollments per day, each requiring manual investigation and correction by the operations team.
How We Diagnosed the Idempotency Gap
Before writing a single line of code, we invested time in understanding how the enrollment flow actually worked end to end. This diagnostic phase – something many teams skip when implementing idempotent API solutions – shaped every architectural decision that followed.
What We Audited
- API log analysis: We traced every enrollment request through the system, identifying retry patterns across the client’s mobile, web, and API gateway layers
- Client behavior mapping: We documented how each client (iOS, Android, web) handled network timeouts, retry intervals, and error recovery
- Downstream system tracing: We mapped every downstream system that reacted to a new enrollment record – billing, roster management, financial aid, and notification services
What We Found
The pattern we uncovered is common across distributed systems. Most developers design APIs assuming a clean, linear request flow. The reality in production is far messier – network timeouts fire before the response arrives, load balancers retry on backends that already processed the request, and connections drop mid-response. The retries themselves are not the problem; retries are necessary for reliability. The problem is when the server cannot recognize them as retries – the core problem that idempotent API design solves.
What Idempotency Means in API Design
An operation is idempotent if performing it multiple times produces the same effect as performing it once – guaranteeing exactly-once processing in REST API design. Some HTTP methods are naturally idempotent: GET reads data without changing it, PUT replaces a resource entirely, and DELETE on an already-deleted resource produces the same final state.
The challenge is that most business operations are POST requests – creating enrollments, registrations, and course assignments – that mutate state in non-idempotent ways. Every call creates something new. The solution is to give the server a way to recognize duplicate requests. That is where the idempotency key pattern comes in. This is the same pattern pioneered by Stripe’s payment API, where every mutating request includes an Idempotency-Key header to guarantee safe retries.

Without idempotency: Each retry to a non-idempotent POST endpoint creates a new enrollment. The student gets enrolled multiple times, billed multiple times, and counted multiple times in capacity calculations.
With idempotency: The first request processes normally, and the result is cached. Every subsequent retry with the same key returns that cached result. The student gets enrolled exactly once – exactly once processed.
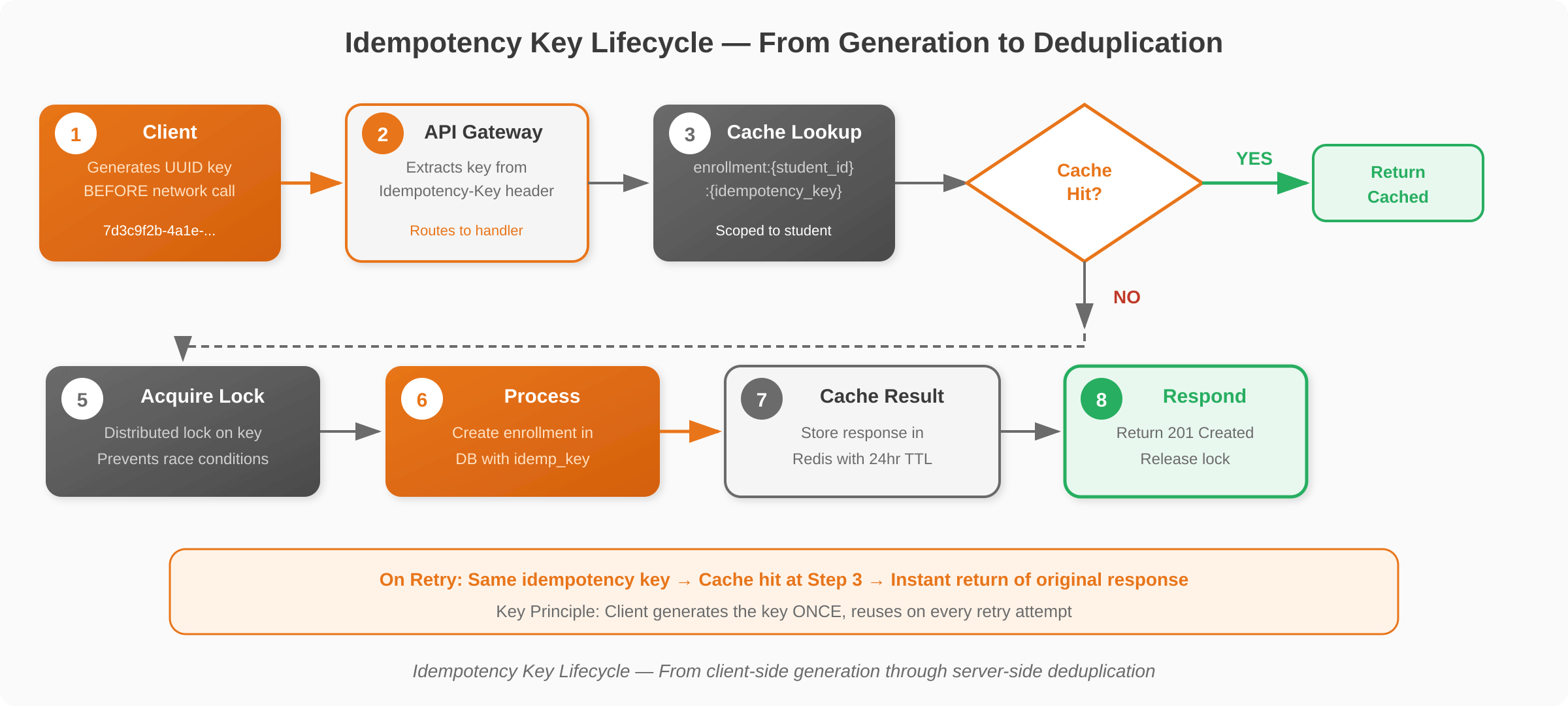
The Three-Layer Idempotent API Architecture
A production-grade idempotent API implementation does not rely on a single mechanism. We designed three layers of defense – not because it is fashionable, but because each layer addresses a distinct failure mode that the others cannot cover.
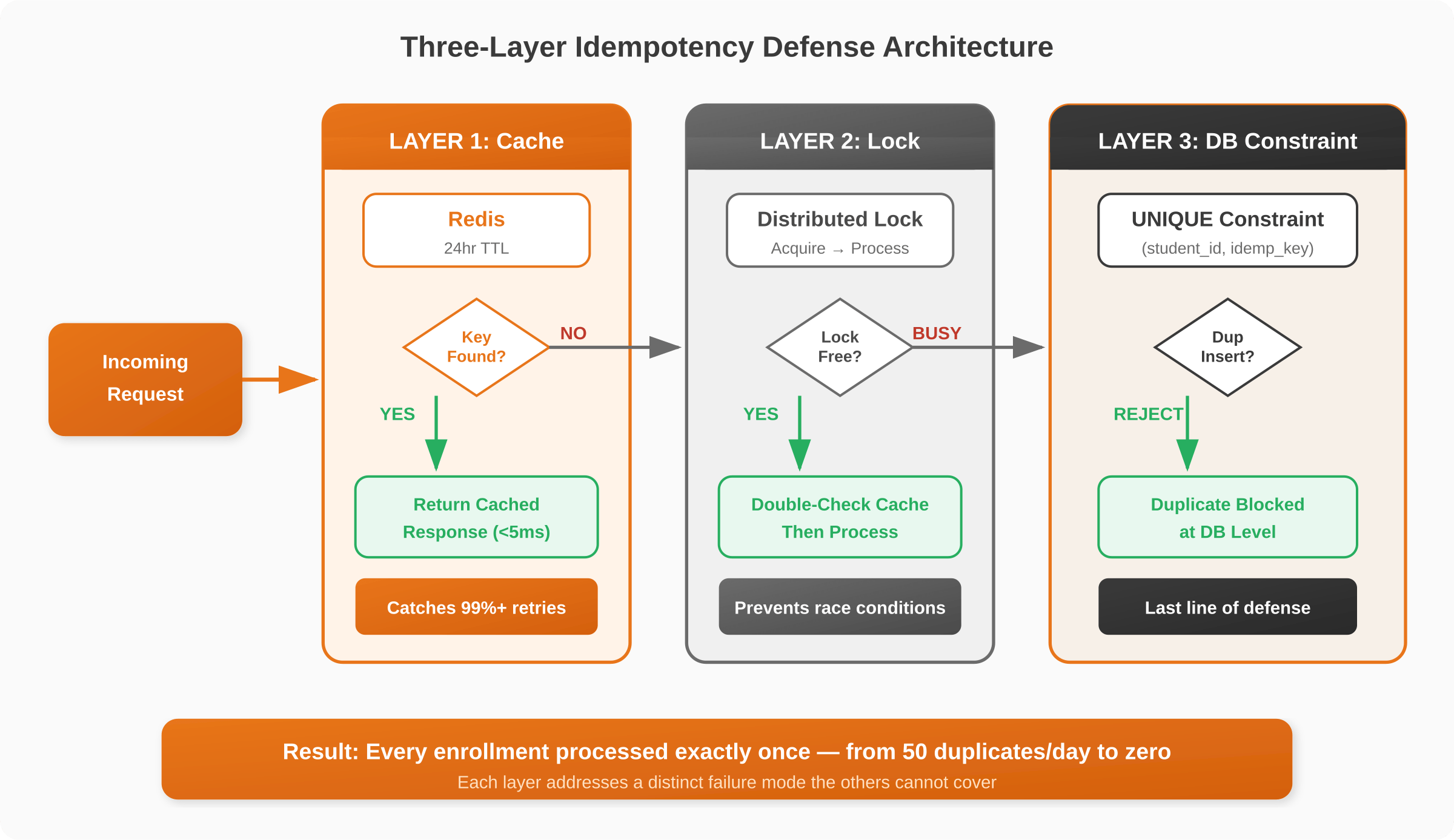
Layer 1 – Redis Cache: The Speed Layer
When a request arrives, the server checks Redis for a cached result tied to that idempotency key. If found, it returns immediately. If not, it proceeds to the next layer. We configured the idempotency key cache TTL at 24 hours – long enough to cover retry storms and delayed processing, short enough to prevent indefinite growth.
This layer handles the vast majority of duplicate requests. At our client’s traffic volume, Redis resolved over 99% of retries without touching the database, keeping response times under 5ms for duplicate requests.
Layer 2 -Distributed Lock: The Race Condition Guard
If the cache misses, the server acquires a distributed lock before processing. This prevents race conditions when multiple retries hit different servers simultaneously. After acquiring the lock, the server double-checks the cache – because another server may have already processed and cached the result while this one was waiting.
This design choice proved its value immediately. During a registration surge after deployment, we observed bursts of 15-20 simultaneous retries for the same enrollment hitting different API servers. Without the distributed lock, at least three of those would have resulted in duplicate records.
Layer 3 – Database Constraint: The Last Line of Defense
As a final safety net, the database table includes a unique constraint on the combination of student_id and idempotency_key. If the cache and lock both fail for any reason, the database itself prevents duplicate inserts.
Over 18 months of production traffic, this constraint caught 3 real incidents when Redis became temporarily unavailable during an AWS outage – exactly the kind of edge case that justifies a layered idempotency architecture.
Key Design Decisions and Trade-offs
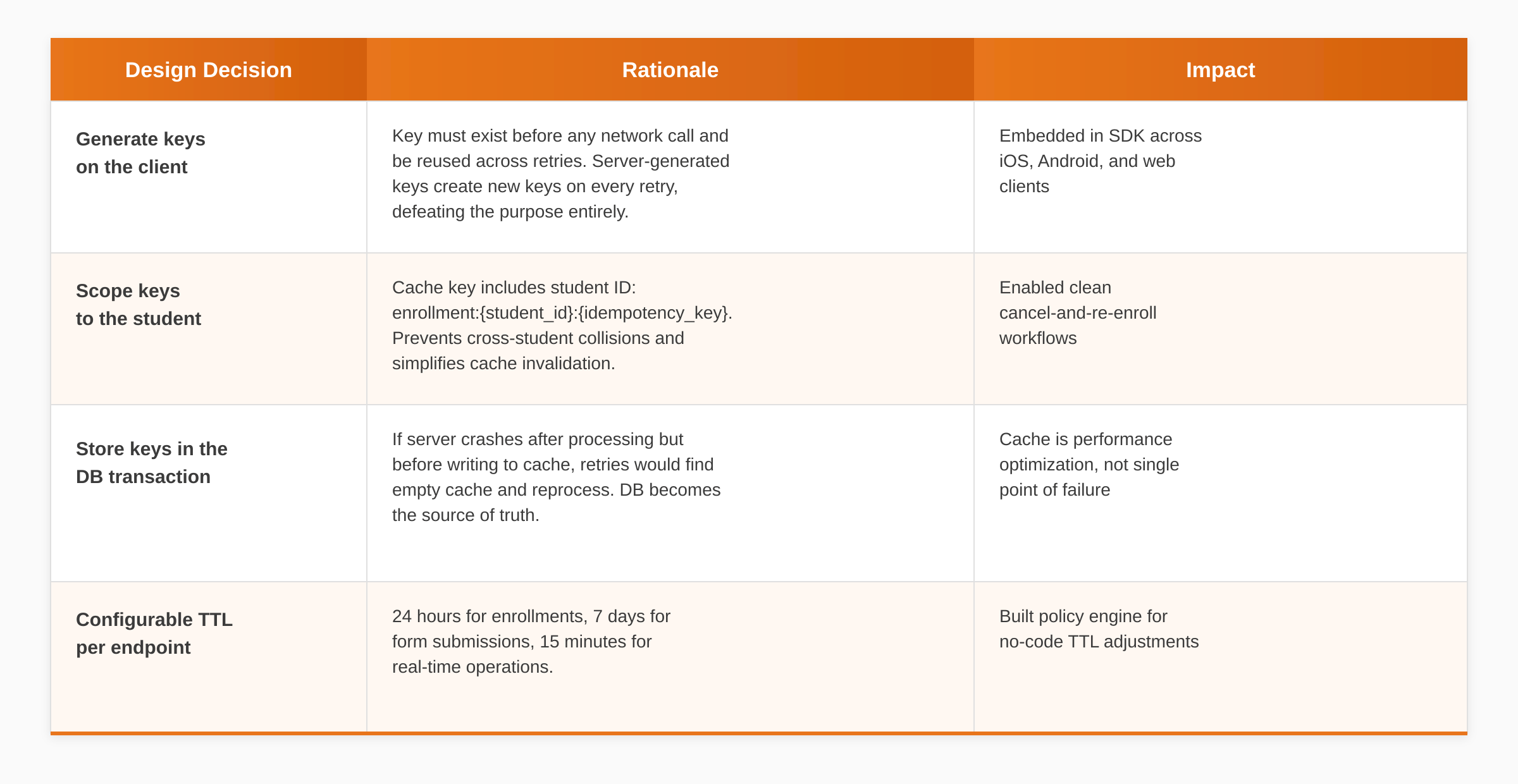
Every architectural choice carried trade-offs. Four decisions had the most significant impact on this idempotent API system’s reliability:
- 24-hour TTL on idempotency keys – balances retry coverage with cache growth management
- Distributed lock with double-check pattern – prevents race conditions while minimizing lock contention
- Strict vs. lenient mode for payload mismatches – 409 Conflict for payments, cached result for enrollments
- Database constraint as final safety net – catches edge cases when Redis is unavailable
Results: Measurable Impact Across the Platform
The impact was immediate and measurable. Within the first week of deployment, the entire duplicate enrollment problem was effectively eliminated through idempotent API design.
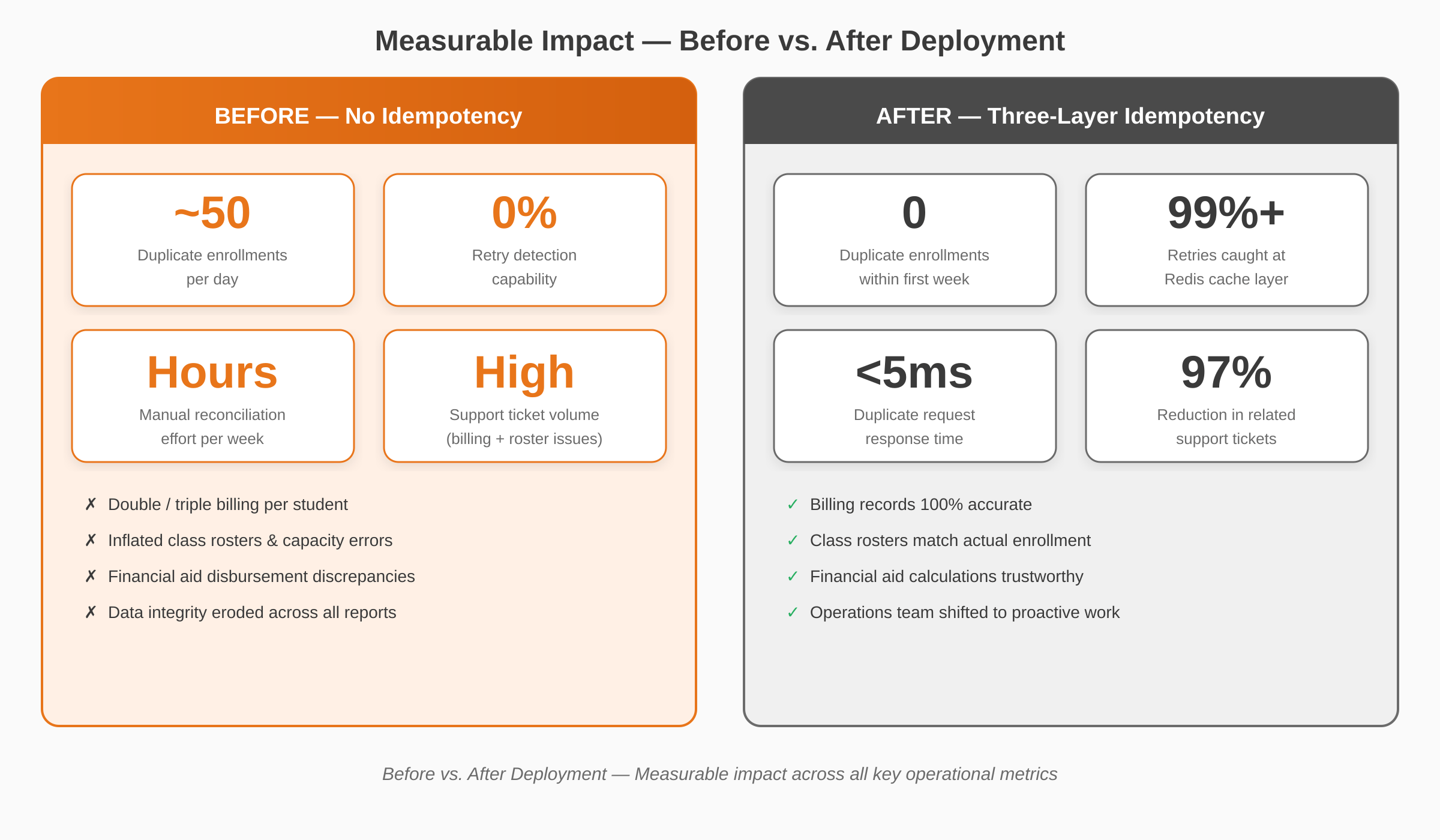
Beyond the numbers, the most significant outcome was that the client’s data became trustworthy. Financial aid calculations, class capacity numbers, and billing records all aligned without manual intervention. The operations team shifted from reactive firefighting to proactive platform improvement.
Edge Cases: How to Handle Real-World Idempotency Scenarios
Payload Mismatch
When a retry arrives with a different request body but the same idempotency key, we offer two modes. Strict mode rejects the request with a 409 Conflict – appropriate for operations where the payload matters, such as payment amounts. Lenient mode returns the cached result from the first attempt – suitable for enrollment-type operations where the first request represents the student’s intent.
Long-Running Operations
When processing takes longer than 30 seconds, holding a distributed lock is impractical. Instead, we implemented an asynchronous status-tracking pattern: the first request creates a job record in the database and returns immediately with a job ID. Retries with the same idempotency key find that record and return the current processing status.
Cross-Service Idempotency
When an enrollment service calls a billing service and then a roster service, we derive child idempotency keys from the parent key – for example, {parent_key}-billing and {parent_key}-roster. This maintains exactly-once processing across service boundaries without requiring a shared cache
Why This Pattern Applies Beyond EdTech
We have deployed identical idempotent API patterns across multiple industries at ScriptsHub Technologies. The failure mode is always the same – a non-idempotent POST endpoint in a distributed system where retries are inevitable:
- EdTech platforms: Duplicate course registrations causing billing discrepancies and broken capacity calculations
- E-commerce platforms: Checkout APIs that decrement inventory on every retry, showing items as “out of stock” when stock is available
- Healthcare systems: Duplicate patient records created by retry storms during high volume intake periods
- Financial services: Double-processed transactions when payment gateways retry on timeout
The three-layer idempotent API architecture – Redis cache, distributed lock, database constraint -addresses all of these scenarios with the same structural pattern.
Lessons Learned
The most significant lesson from this engagement was about observability. We should have instrumented idempotency metrics and retry analytics from day one. We deployed the idempotency layer first and added detailed monitoring in the third sprint. During that gap, we missed the opportunity to quantify exactly how many duplicates the system was catching per hour – data that would have strengthened the case for extending this pattern to other APIs sooner.
Every new engagement now begins with idempotency observability alongside the first endpoint.
The three layers of a production-grade idempotent API architecture are: a Redis cache for sub-5ms duplicate detection that resolves over 99% of retries without touching the database; a distributed lock with double-check pattern to prevent race conditions when simultaneous retries hit different servers; and a database unique constraint as the final safety net that catches edge cases when upstream layers are unavailable. Together, these three layers guarantee exactly-once processing for non-idempotent POST endpoints in distributed systems.
Is Your API Layer Creating Data Integrity Problems?
If your team is spending more time reconciling duplicate records than building features – or if your support team is fielding complaints that trace back to retry-related data inconsistencies – the root cause is likely a missing idempotency layer.
ScriptsHub Technologies delivers production-grade idempotent API architectures across EdTech, healthcare, and financial services. We offer a complimentary API Resilience Assessment – a focused review of your current endpoint design, retry handling, and deduplication gaps, with a prioritized implementation roadmap.
→ Connect with us at info@scriptshub.net or visit www.scriptshub.net
Frequently Asked Questions
-
What is an idempotent API and why does it matter for distributed systems?
An idempotent API guarantees that performing the same operation multiple times produces the same result as performing it once. This is critical in distributed systems where network failures, load balancer retries, and client timeouts routinely cause duplicate requests. Without idempotency, every retry to a POST endpoint creates a new record – leading to duplicate enrollments, double billing, or corrupted inventory data. Idempotent API design ensures exactly-once processing regardless of how many times a request is retried.
-
What is an idempotency key and how does it work?
An idempotency key is a unique identifier – typically a UUID – that the client includes with each API request. The server uses this key to determine whether a request has already been processed. If the key is found in the cache or database, the server returns the previously stored result instead of processing the request again. This pattern transforms non-idempotent POST endpoints into idempotent operations by giving the server a reliable mechanism for duplicate request detection.
-
How does Redis help with API idempotency?
Redis serves as the first layer in a production-grade idempotent API architecture. When a request arrives, the server checks Redis for a cached result tied to the idempotency key. If found, it returns immediately with sub-5ms response times. If not found, the request proceeds to processing. At production traffic volumes, Redis typically resolves over 99% of duplicate retries without touching the database – making it the most performance-critical layer of the idempotency stack.
-
What is the difference between client-side and server-side deduplication?
Client-side deduplication – such as frontend throttling or disabling submit buttons – cannot prevent duplicates caused by load balancer retries, connection drops mid-response, or requests routed to different backend servers. Server-side deduplication using idempotency keys, distributed locks, and database constraints is the only reliable approach because it operates at the point where state is actually mutated. Client-side measures reduce unnecessary requests but cannot guarantee exactly-once processing.
-
How do you handle idempotency across multiple microservices?
When a parent service calls multiple downstream services (e.g., enrollment → billing → roster), cross-service idempotency is maintained by deriving child idempotency keys from the parent key – for example, {parent_key}-billing and {parent_key}-roster. Each downstream service independently validates its own idempotency key, ensuring exactly-once processing across service boundaries without requiring a shared cache or distributed transaction coordinator.
-
Why do most API retry handling solutions fail in production?
Most retry handling solutions fail because they rely on a single mechanism – typically either a cache or a database constraint alone. A cache-only approach fails when the cache is unavailable (e.g., during a Redis outage). A database-only approach creates performance bottlenecks under high retry volumes. A production-grade solution requires three layers: a Redis cache for speed, a distributed lock for race condition prevention, and a database constraint as the final safety net. This layered approach has proven reliable across 18 months of production traffic at ScriptsHub Technologies.
Leave a Reply